
While text-to-image diffusion models have been shown to achieve state-of-the-art results in image synthesis, they have yet to prove their effectiveness in downstream applications. Previous work has proposed to generate data for image classifier training given limited real data access. However, these methods struggle to generate in-distribution images or depict fine-grained features, thereby hindering the generalization of classification models trained on synthetic datasets. We propose DataDream, a framework for synthesizing classification datasets that more faithfully represents the real data distribution when guided by few-shot examples of the target classes. DataDream fine-tunes LoRA weights for the image generation model on the few real images before generating the training data using the adapted model. We then fine-tune LoRA weights for CLIP using the synthetic data to improve downstream image classification over previous approaches on a large variety of datasets. We demonstrate the efficacy of DataDream through extensive experiments, surpassing state-of-the-art classification accuracy with few-shot data across 7 out of 10 datasets, while being competitive on the other 3. Additionally, we provide insights into the impact of various factors, such as the number of real-shot and generated images as well as the fine-tuning compute on model performance. The code is available at https://github.com/ExplainableML/DataDream.
Training with Synthetic Data
Recent advances in text to image models have facilitated the generation of unprecedentedly photorealistic images. By generating higher quality, more controllable images, the usefulness of synthetic images for model training increases. Synthetic data is highly appealing as a data collection method, due to its relative inexpensiveness compared to real data.
However, in a zero-shot setting where we have no real examples of the target classes, the generation model can be prone to misunderstanding the classes, as shown in the figure below. Unfortunately, misunderstood classes have limited training usefulness.
In this case, few-shot data can help align synthetic images with the target distribution. Previous methods used few-shot data to modify the generation model inputs (e.g. captions, latent noise), but kept the generation model parameters fixed. Hence, if the generation model fundamentally misunderstands the classes, generation ability will not be improved.

Adapting with Few-shot Data
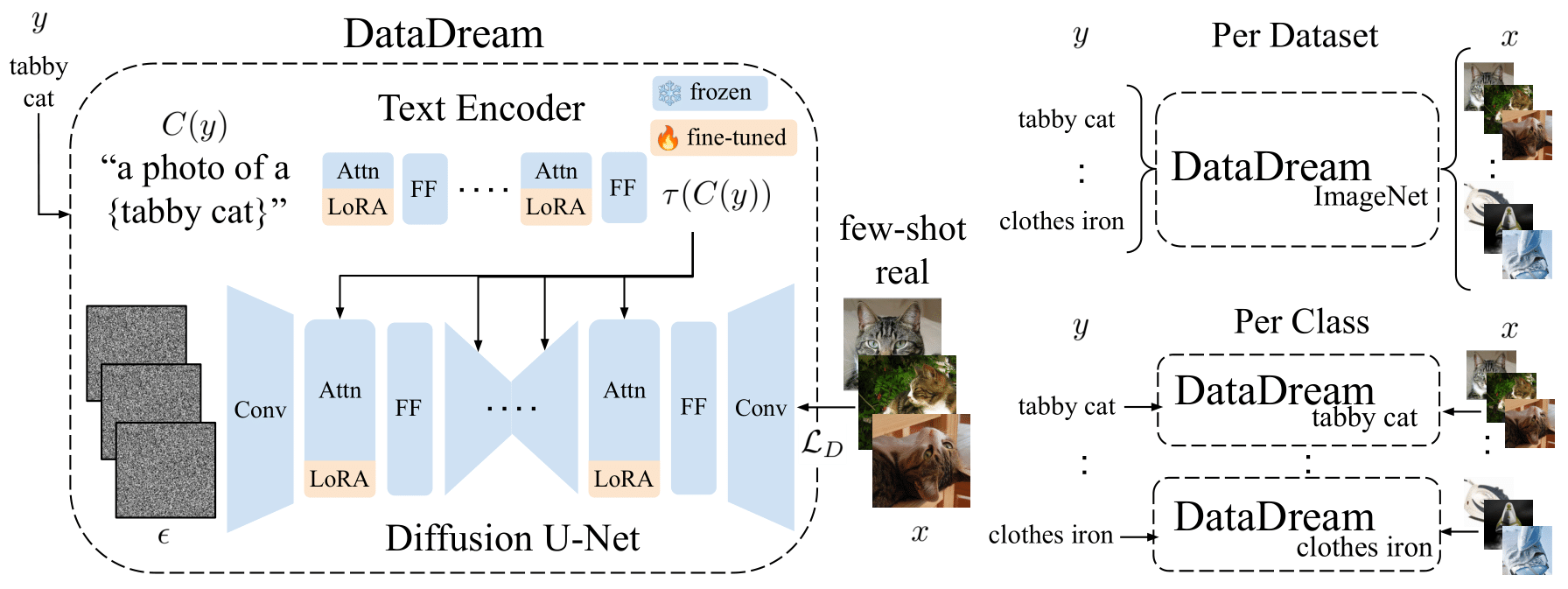
With DataDream, we propose to adapt the generation model to better understand the target classes using the few-shot data. To this end, we use LoRA to fine-tune the image generation model given the few-shot data. Once fine-tuned, we use these updated parameters to generate the images for downstream classification training.
We implement training in two ways: class-wise and dataset-wise. For class-wise training, we fine-tune the generation model for each class individually, allowing maximum parameter capacity to adapt to the unique class. Comparatively, dataset-wise training fine-tunes the model given the full few-shot dataset, which allows information to be shared between classes and helps prevent the overfitting to which the model is susceptible in the few-shot domain.
The Results of DataDream
To test our generation method, we use LoRA to fine-tune CLIP on the generated images.
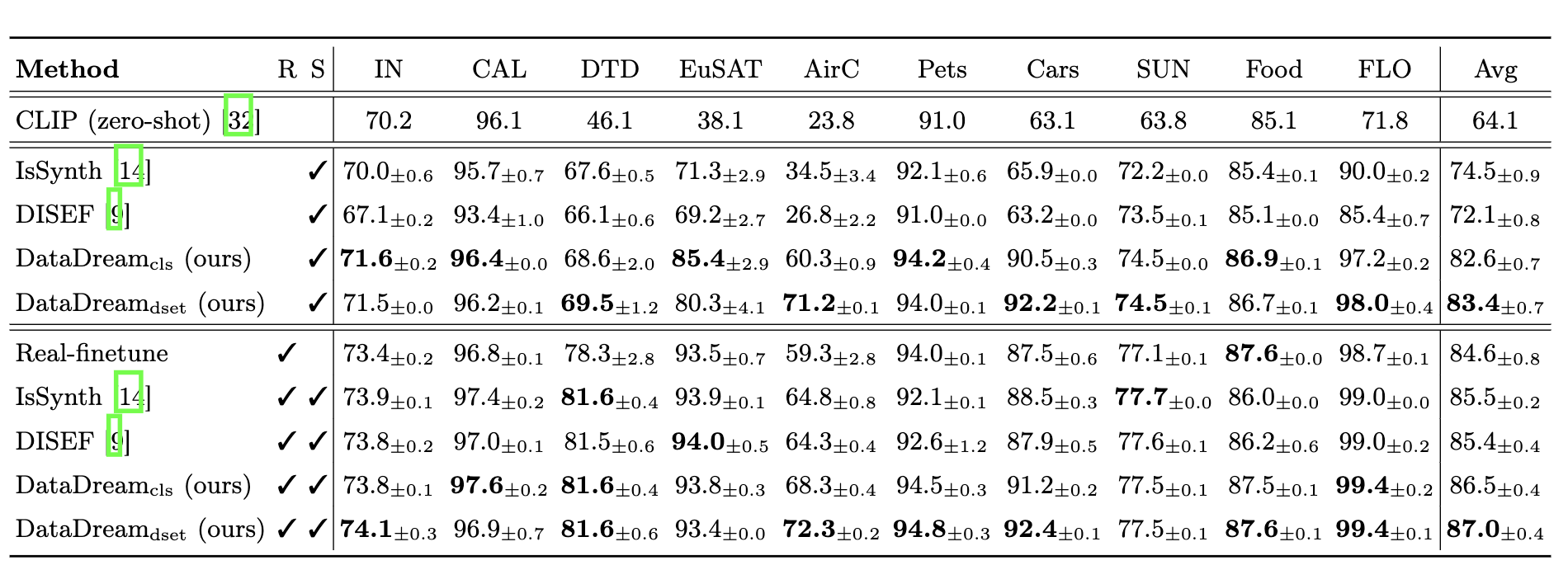
With DataDream, we achieve SOTA performance in 10 out of 10 datasets when training the classifier on synthetic data only (S symbolizing synthetic and R symbolizing real data in the results figure below). In the synthetic + real setting, we also achieve SOTA in 8 out of 10 datasets. The superiority of the class-wise vs. dataset-wise method is dataset dependant.
 Qualitatively, we find that images generated by DataDream are better able to match the few-shot distribution than the previous SOTA few-shot methods, IsSynth and DISEF, as shown in the figure below. The figure includes the exact real images used as few-shot examples for the Sword Lily class in the Oxford Flowers102 dataset.
As we increase the number of shots, we see that the images better fit the target distribution. At a single shot, the class-wise version of DataDream recreates the single flower it was shown, while the dataset-wise version seems to have taken on some incorrect petal shaping information from the other classes. However, as the number of shots increases, these deficiencies improve and by sixteen shots, both methods are consistently creating accurate and in-distribution images.
Qualitatively, we find that images generated by DataDream are better able to match the few-shot distribution than the previous SOTA few-shot methods, IsSynth and DISEF, as shown in the figure below. The figure includes the exact real images used as few-shot examples for the Sword Lily class in the Oxford Flowers102 dataset.
As we increase the number of shots, we see that the images better fit the target distribution. At a single shot, the class-wise version of DataDream recreates the single flower it was shown, while the dataset-wise version seems to have taken on some incorrect petal shaping information from the other classes. However, as the number of shots increases, these deficiencies improve and by sixteen shots, both methods are consistently creating accurate and in-distribution images.

Want to know more?
For many more details, background, and analysis, please check out our paper to be published in ECCV 2024! It is available at https://arxiv.org/abs/2407.10910. If you are attending, we are always excited to discuss and answer questions. Our code is available on GitHub as well, at https://github.com/ExplainableML/DataDream.