
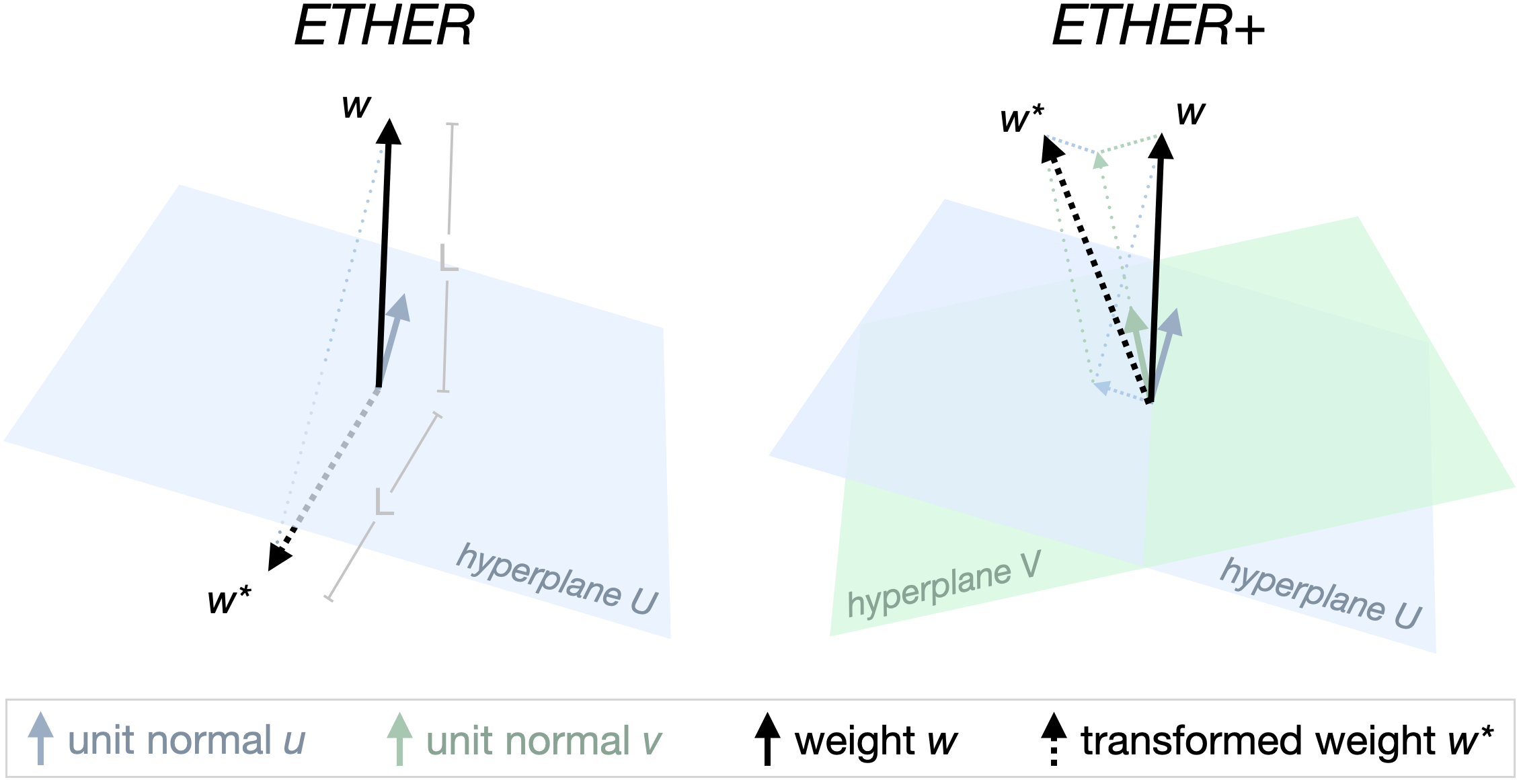
Parameter-efficient finetuning (PEFT) has become ubiquitous to adapt foundation models to downstream task requirements while retaining their generalization ability. However, the amount of additionally introduced parameters and compute for adaptation and hyperparameter searches can explode quickly, especially when deployed at scale to serve numerous individual requests. To ensure effective, parameter-efficient, and hyperparameter-robust adaptation, we propose the ETHER transformation family, which performs Efficient fineTuning via HypErplane Reflections. By construction, ETHER transformations require very few parameters, are unlikely to catastrophically overwrite model weights, and robust to hyperparameter and learning rate choices. In particular, we introduce ETHER and its relaxation ETHER+, which match or outperform existing PEFT methods with significantly fewer parameters (up to 250 imes lower than OFT) across multiple image synthesis and natural language tasks without exhaustive hyperparameter tuning. Finally, we investigate the recent emphasis on Hyperspherical Energy retention for adaptation and raise questions on its practical utility.